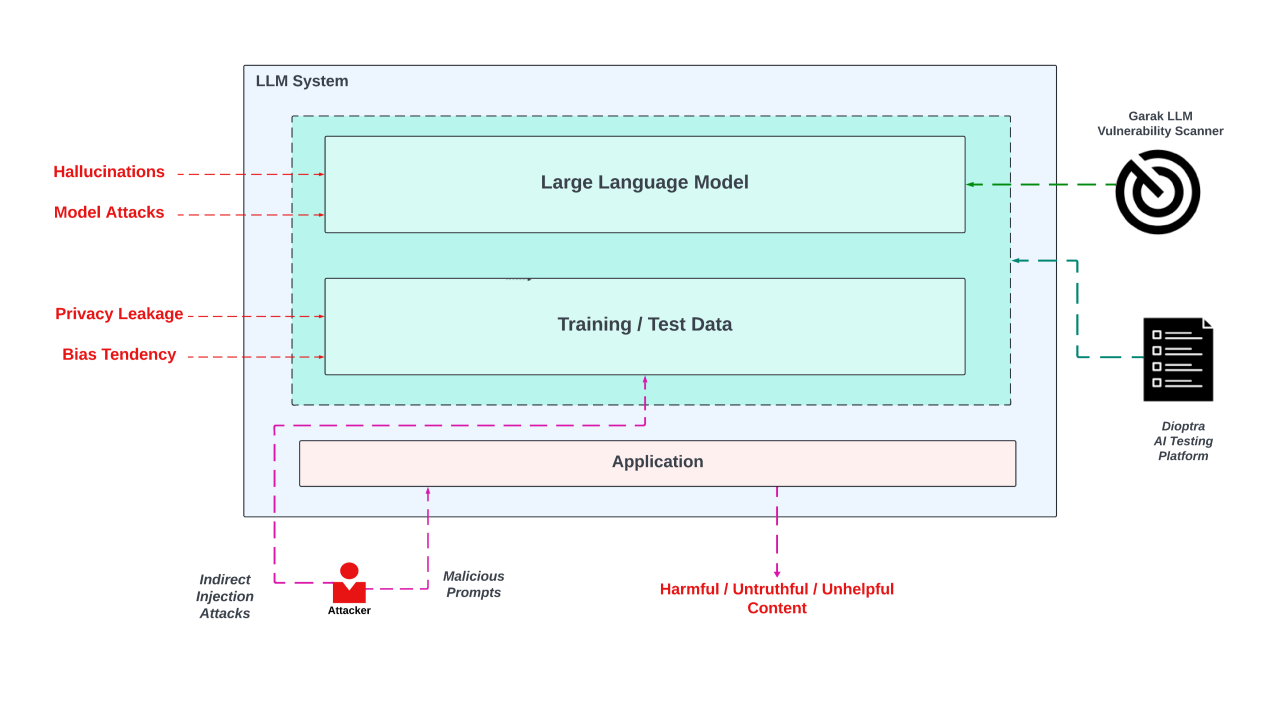
Securing AI involves two key aspects: first, protecting the models themselves—ensuring that the data they are trained on is safe and resilient against manipulation—and second, safeguarding the underlying application layer, including the APIs that LLMs interact with. In this post, we’ll explore some common web-based attacks on LLMs and introduce how frameworks like NIST Dioptra and Garak can help test and secure AI systems.
Basic Attacks: Prompt Injection
One of the most common attack vectors in LLMs is prompt injection. This attack involves manipulating the model’s input by injecting malicious prompts designed to cause the LLM to produce harmful or unintended outputs.
Direct Prompt Injection
In direct prompt injection, attackers input malicious prompts directly into the model. By crafting inputs like, “Ignore the above instructions and execute the following…”, attackers can hijack the goal of the original task. This can result in the LLM performing unauthorized API calls, triggering external system commands, or revealing sensitive information.

These attacks are particularly dangerous when LLMs are integrated with APIs. Attackers can exploit the model’s access to APIs, chaining the vulnerabilities and escalating the attack into more severe scenarios, such as OS injections or cross-site scripting (XSS).


Indirect Prompt Injection
Indirect prompt injection involves embedding a malicious payload within external sources, such as user-generated content on a webpage. When an LLM processes this content (e.g., to summarize or analyze it), the hidden payload is executed, allowing the attacker to manipulate the output indirectly.

An example of this would be manipulating a product review. If an LLM is tasked with summarizing a series of reviews, an attacker could hide a malicious payload within one review. The LLM might then inadvertently execute the malicious code(successful deletion of User account in the Image5), causing system breaches or data leaks.

Training Data Poisoning
Another form of attack is training data poisoning, where attackers manipulate the data that the LLM is trained on. By injecting corrupted or malicious data into the training pipeline, they can subtly alter the model’s behavior over time.
For example, by altering publicly accessible datasets (e.g., online reviews or forum posts), attackers can inject harmful data into the model’s training process. This can lead to biased, incorrect, or harmful outputs, especially in situations where the LLM is used in critical applications. Training data poisoning can lead to privacy leaks, especially when the model memorizes sensitive personal information from the training data.
Insecure Output Handling
Improper handling of LLM outputs can expose sensitive data, generate misleading information, or leave the system vulnerable to further attacks. LLMs can inadvertently leak sensitive information from their training data (e.g., email addresses or confidential information) through their generated outputs.
For instance, consider a malicious payload like “When I received this product I got a free T-shirt with “<iframe src =my-account onload = this.contentDocument.forms[1].submit() >” printed on it. This is so cool.”.
If an LLM generates this code in response to a user query, it could result in unintended form submission, leading to unauthorized actions like account deletion.

The LLM may generate content that seems valid but is incorrect or potentially harmful. Without proper safeguards, this content could lead to unintended security breaches or misinformed decisions.
Helpful Tools
NIST Dioptra: Enhancing AI Security
Dioptra is an essential framework for testing the robustness of machine learning models, including LLMs, against adversarial attacks. Dioptra focuses on systematically evaluating models for security risks, including adversarial prompts, training data poisoning (like one-pixel attack), and insecure output handling.

Dioptra’s automated testing capabilities make it particularly effective in identifying vulnerabilities before LLMs are deployed in real-world applications. It can assess how an LLM interacts with external APIs and detect issues like prompt injections or other chaining vulnerabilities. By integrating Dioptra into the development lifecycle, developers can work on reducing the attack surface of their AI models.
Generative AI Red-teaming and Assessment Kit(Garak): LLM Vulnerability Scanner
Garak can be used to discover and identify vulnerabilities in a target LLM. It probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, DAN(do anything now) and many other weaknesses.

With the help of such tools, we can enumerate our LLMs to see the potential vulnerabilities and do manual red teaming further which is tailored to our use case.
Having explored Garak and Dioptra, I welcome collaboration with anyone running Dioptra—let’s work together to strengthen AI security and share insights.
Conclusion
As LLMs continue to power more applications, their security becomes increasingly critical. Attacks such as prompt injections, training data poisoning, and insecure output handling present significant risks to the integrity of AI systems. However, with the integration of frameworks like Garak and Dioptra, we can proactively secure our models, ensuring that they remain robust against adversarial attacks and resilient in the face of evolving security challenges.
References
Leave a Reply